
Python:Matplotlib 和 Seaborn (二十五)
条形图
条形图用于描述分类变量的分布情况。在条形图中,分类变量的每个级别用长条表示,高度表示数据在该级别的出现频率。我们可以通过 seaborn 的 countplot 函数创建基本的频率条形图:
sb.countplot(data = df, x = 'cat_var')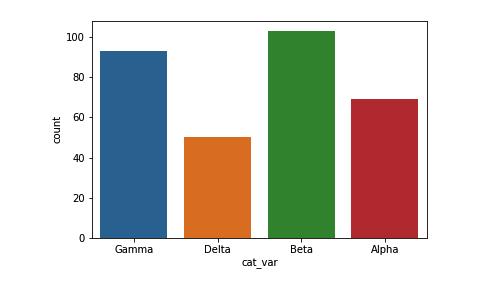
对于给定的示例,可以看出,β 级别频率最高,超过 100 次,然后是 γ 和 α,δ 的频率最低,大约为 50。默认情况下,每个类别都用不同的颜色标注。这样的话,在这些类别标签之间建立关联性以及在图中用更多的变量编码时会比较方便。否则,建议简化图表,将所有长条都用相同的颜色标注,可以减少不必要的干扰。我们可以使用 "color" 参数设置长条颜色:
base_color = sb.color_palette()[0]
sb.countplot(data = df, x = 'cat_var', color = base_color)color_palette 返回一个 RGB 元组列表,每个元组指定一个颜色。数字参数返回当前/默认调色板,我们将第一个颜色设为所有长条的颜色。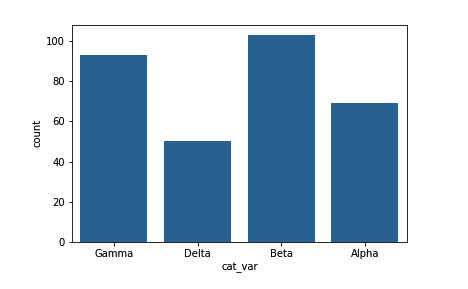
对于条形图,我们可能需要执行的一个操作是以某种方式对数据排序。对于名目数据,一种常见操作是按照频率对数据排序。我们的数据采用的是 pandas DataFrame,因此我们可以使用各种 DataFrame 方法来计算和得出排序方式,然后使用 "order" 参数设置排序方式:
base_color = sb.color_palette()[0]
cat_order = df['cat_var'].value_counts().index
sb.countplot(data = df, x = 'cat_var', color = base_color, order = cat_order)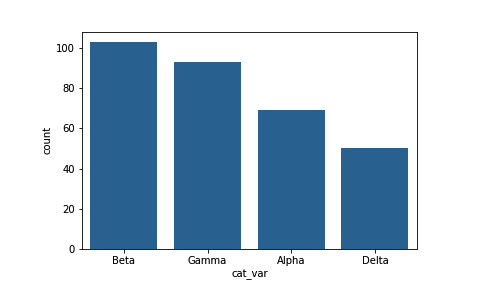
对于有序数据,我们可能需要根据变量顺序对长条排序。虽然我们像上面的示例一样按照频率对级别排序,但是我们通常关心的是频率最高的值是否是很高的级别、很低的级别,等等。在这种情况下,最佳做法是将列转换为有序分类数据类型。默认情况下,pandas 将字符串数据读取为对象类型,并按照唯一值的顺序绘制长条。通过以这种方式转换数据,我们拥有针对所有图形的排序方式,而不用不断指定 "order" 参数。
# 本方法要求 pandas 0.21 或更高版本
level_order = ['Alpha', 'Beta', 'Gamma', 'Delta']
ordered_cat = pd.api.types.CategoricalDtype(ordered = True, categories = level_order)
df['cat_var'] = df['cat_var'].astype(ordered_cat)
## 如果你的 pandas 为 0.20.3 或更低版本,请使用这种方法:
# df['cat_var'] = df['cat_var'].astype('category', ordered = True,
# categories = level_order)
base_color = sb.color_palette()[0]
sb.countplot(data = df, x = 'cat_var', color = base_color)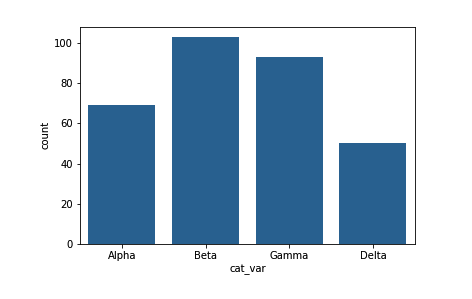
如果你发现你需要按照不同的顺序对有序分类数据排序,始终可以通过设置 "order" 参数临时替换数据类型,如上所示。
其他变量
如果数据是 pandas Series、一维 NumPy 数组或列表形式,你可以将其设为 countplot 函数的第一个参数,如以下 Series data_var 所示:
sb.countplot(data_var)如果有很多个分类级别,或者类别名称很长,那么刻度标记可能会紧挨在一起。一种解决方式是创建横条图。在横条图中,每个长条的长度(而不是高度)表示频率。在代码中,你可以设置在参数 "y" 上绘制变量,而不是在参数 "x" 上绘制数据或变量:
base_color = sb.color_palette()[0]
sb.countplot(data = df, y = 'cat_var', color = base_color)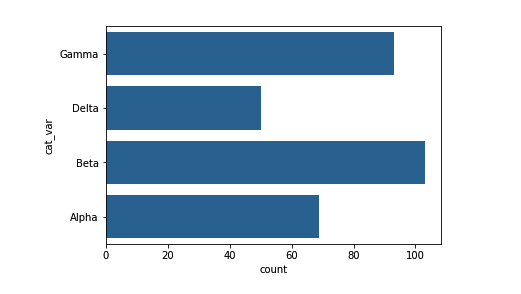
此外,你可以使用 matplotlib 的 xticks 函数及其 "rotation" 参数更改绘制标签的方向(与水平方向的逆时针夹角度数):
base_color = sb.color_palette()[0]
sb.countplot(data = df, x = 'cat_var', color = base_color)
plt.xticks(rotation = 90)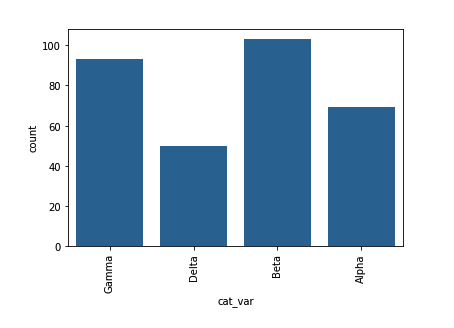
绝对频率和相对频率
默认情况下,seaborn 的 countplot 函数将以绝对频率(或纯粹计数)总结和绘制数据。在某些情形下,你可能需要了解数据分布或者用在总体中所占的比例比较级别。在这种情形下,你需要用相对频率绘制数据,高度表示数据在每个级别的比例,而不是绝对计数。
在条形图中用相对频率绘制数据的一种方式是用比例重新标记计数坐标轴。底层数据不变,只是轴刻度的比例会发生变化。
# get proportion taken by most common group for derivation
# of tick marks
n_points = df.shape[0]
max_count = df['cat_var'].value_counts().max()
max_prop = max_count / n_points
# generate tick mark locations and names
tick_props = np.arange(0, max_prop, 0.05)
tick_names = ['{:0.2f}'.format(v) for v in tick_props]
# create the plot
base_color = sb.color_palette()[0]
sb.countplot(data = df, x = 'cat_var', color = base_color)
plt.yticks(tick_props * n_points, tick_names)
plt.ylabel('proportion')xticks 和 yticks 函数不仅仅会旋转刻度标签。你还可以获取和设置它们的位置及标签。第一个参数表示刻度位置:在此例中,刻度比例翻倍后变回计数比例。第二个参数表示刻度名称:在此例中,刻度比例的格式为精确到两位小数的字符串。
我还添加了 ylabel 调用,表明我们不再使用绝对计数。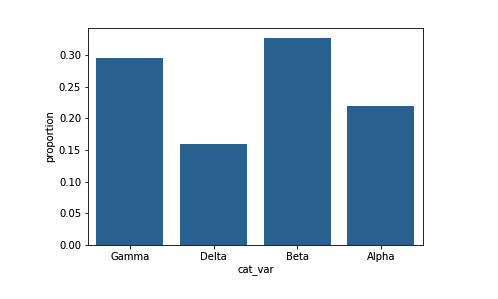
其他版本
你可以在长条上使用文本注释标记频率,而不是以相对频率标尺绘制数据。这需要编写一个循环来遍历刻度位置和标签,并为每个长条添加一个文本元素。
# create the plot
base_color = sb.color_palette()[0]
sb.countplot(data = df, x = 'cat_var', color = base_color)
# add annotations
n_points = df.shape[0]
cat_counts = df['cat_var'].value_counts()
locs, labels = plt.xticks() # get the current tick locations and labels
# loop through each pair of locations and labels
for loc, label in zip(locs, labels):
# get the text property for the label to get the correct count
count = cat_counts[label.get_text()]
pct_string = '{:0.1f}%'.format(100*count/n_points)
# print the annotation just below the top of the bar
plt.text(loc, count-8, pct_string, ha = 'center', color = 'w')我使用 .get_text()方法获取类别名称,从而获取每个分类等级的计数。最后,我使用 text 函数输出每个百分比,并将 x 坐标、y 坐标和字符串作为该函数的三个主要参数。
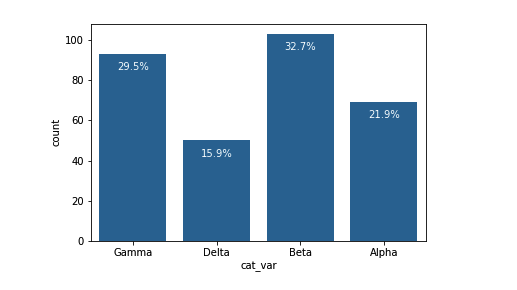
计算缺失的数据
应用条形图的一个有趣方式是可视化缺失的数据。我们可以使用 pandas 函数创建一个标签,每列包含缺失值的数量。
df.isna().sum()
如果我们想可视化这些缺失的值计数呢?我们可以将变量名当做分类变量的级别,并创建条形图。然而,由于这些数据并不整洁,未经处理也未经归纳,因此我们需要使用另一个绘制函数。 Seaborn 的 barplot 函数旨在描述一个定量变量相对于另一个定量变量级别的直观状况,可以用在此处。
na_counts = df.isna().sum()
base_color = sb.color_palette()[0]
sb.barplot(na_counts.index.values, na_counts, color = base_color)该函数的第一个参数包含 x 值(列名称),第二个参数包含 y 值(计数)。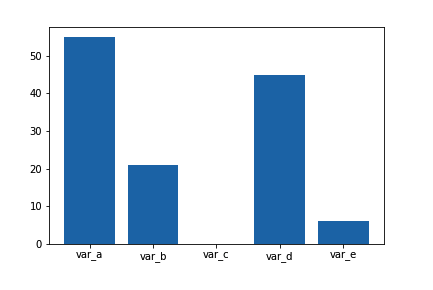
一般而言,如果你的数据已经过整理归纳并且你依然想要绘制条形图,那么该函数很有用。但是如果数据尚未归纳,则使用 countplot函数,这样就不需要进行额外的归纳工作。此外,你将在下节课了解 barplot 的主要作用是什么,届时我们将讨论如何调整单变量图以绘制双变量数据。
为者常成,行者常至
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)


