
自动驾驶-第二阶段-BEV 感知 + VAD 复现实战课程
第二阶段:BEV感知 + VAD复现实战课程
从单摄像头到多视角BEV,从简单模仿学习到工业级端到端自动驾驶
前置要求: 完成第一阶段(CARLA闭环Demo),熟悉PyTorch、nuScenes数据集概念
时间规划: 3-4周(每天2-4小时)
硬件要求: RTX 3090 24GB(本地)或等效云GPU
Week 1:BEV感知——让车"看懂"整个世界
Day 1-2:理解BEV感知的核心思想
什么是BEV?为什么要用BEV?
在第一阶段中,我们的模型只用了一个前视摄像头——这就像你开车只看前方,不看左右后视镜。真正的自动驾驶车有6个摄像头(前、前左、前右、后、后左、后右),覆盖360度视野。
问题来了: 6个摄像头产生6张图片,每张图片里的"一辆车"在不同视角下长得完全不同。怎么把它们统一起来?
答案就是BEV(Bird's Eye View,鸟瞰视角)。 把所有摄像头的信息"压扁"到一个俯视图上——就像你站在楼顶往下看,每辆车只是一个矩形,不管从哪个角度看都一样。
摄像头视角(透视图): BEV视角(俯视图):
远处的车很小、近处的车很大 → 每辆车按真实大小显示
有遮挡、有畸变 → 无遮挡、无畸变
6张不同角度的图片 → 1张统一的俯视图类比理解: 你玩《王者荣耀》时,屏幕上角的小地图就是BEV——它用俯视角度让你知道所有队友和敌人的绝对位置。而你操作英雄时看到的第三人称视角就是透视图。自动驾驶需要的就是从"英雄视角"到"小地图"的转换。
BEVFormer是怎么做的?
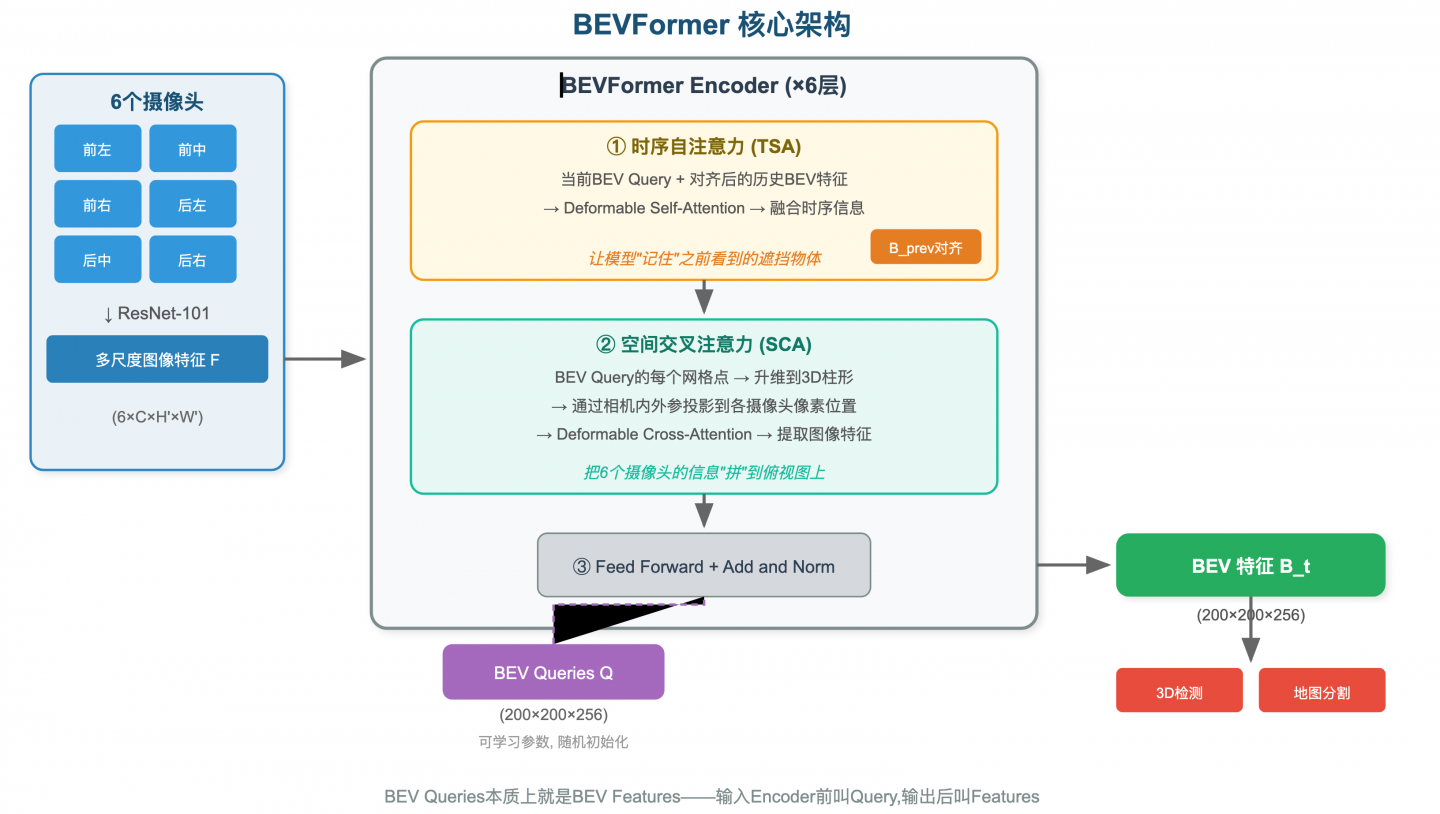
BEVFormer是目前最经典的BEV感知方法(ECCV 2022),也是UniAD、VAD等端到端系统的"眼睛"。它的核心思想用三句话概括:
第一步:图像特征提取。 用ResNet从6张图片中分别提取特征。这一步跟普通图像识别没区别。
第二步:空间交叉注意力(Spatial Cross-Attention)。 这是BEVFormer的核心创新。在BEV平面上预设一组网格点(比如200×200个点),每个点代表真实世界中的一个位置。对于每个BEV点,通过相机内外参数计算它在哪个摄像头的哪个像素位置,然后去那个位置"取"特征。
# 伪代码:空间交叉注意力的直觉
for each bev_point in bev_grid: # 遍历BEV网格上的每个点
world_x, world_y = bev_point # 这个点在真实世界的坐标
for each camera in 6_cameras: # 检查每个摄像头
pixel_u, pixel_v = project(world_x, world_y, camera) # 投影到像素坐标
if pixel_in_image(pixel_u, pixel_v): # 如果这个点在该摄像头视野内
feature = sample(image_feature[camera], pixel_u, pixel_v) # 取特征
bev_feature[bev_point] += attention(feature) # 用注意力加权第三步:时序自注意力(Temporal Self-Attention)。 把上一帧的BEV特征和当前帧融合,让模型"记住"之前看到的东西。比如一辆车被大卡车挡住了,但上一帧它还没被挡住——时序融合让模型知道那辆车还在。
概念解释:内参和外参
内参(Intrinsic): 摄像头自身的参数,包括焦距、光心位置。它决定了"3D世界中的一个点会落在图像的哪个像素上"。类比:你的眼睛近视度数就是内参的一种。
外参(Extrinsic): 摄像头相对于车辆的安装位置和朝向。前摄像头朝前、左摄像头朝左——这些就是外参。内参+外参合在一起,就能把BEV平面上的任何一个点投影到对应摄像头的像素坐标上。
实操:用nuScenes Mini数据集跑通BEVFormer推理
Step 1:下载nuScenes Mini数据集
# Mini数据集只有约4GB,适合快速验证
# 去 https://www.nuscenes.org/ 注册账号后下载
# 需要下载:v1.0-mini + can_bus
mkdir -p ~/data/nuscenes
# 解压 zip
unzip can_bus.zip
# 解压 tgz(tar+gzip)
tar -zxvf v1.0-mini.tgz
# 解压后目录结构:
# ~/data/nuscenes/
# ├── maps/
# ├── samples/
# ├── sweeps/
# ├── v1.0-mini/
# └── can_bus/Step 2:搭建BEVFormer环境
conda create -n bevformer python=3.8 -y
conda activate bevformer
# PyTorch + CUDA
pip install torch==1.10.0+cu113 torchvision==0.11.0+cu113 \
-f https://download.pytorch.org/whl/torch_stable.html
# OpenMMLab依赖(版本必须严格匹配!)
pip install mmcv-full==1.4.0 \
-f https://download.openmmlab.com/mmcv/dist/cu113/torch1.10.0/index.html
pip install mmdet==2.14.0
pip install mmsegmentation==0.14.1
# mmdetection3d(必须用指定版本)
git clone https://github.com/open-mmlab/mmdetection3d.git
cd mmdetection3d
git checkout v0.17.1
python setup.py install
cd ..
# 其他依赖
pip install nuscenes-devkit==1.1.10 numpy==1.19.5 \
scikit-image==0.19.0 timm setuptools==59.5.0⚠️ 版本地雷警告: BEVFormer对依赖版本极其敏感。mmcv、mmdet、mmdet3d的版本三者必须匹配,换任何一个都可能报ModuleNotFoundError。上面的版本组合是经过大量社区验证的稳定组合,不要自己"升级"。
Step 3:克隆BEVFormer并下载预训练权重
git clone https://github.com/zhiqi-li/BEVFormer.git
cd BEVFormer
# 下载预训练权重
mkdir ckpts && cd ckpts
wget https://github.com/zhiqi-li/storage/releases/download/v1.0/bevformer_r101_dcn_24ep.pth
cd ..Step 4:数据预处理
# 创建软链接
ln -s ~/data/nuscenes data/nuscenes
ln -s ~/data/nuscenes/can_bus data/can_bus
# 生成标注文件
python tools/create_data.py nuscenes \
--root-path ./data/nuscenes \
--out-dir ./data/nuscenes \
--extra-tag nuscenes \
--version v1.0-mini \
--canbus ./dataStep 5:运行推理测试
# 用预训练权重跑推理
python tools/test.py \
projects/configs/bevformer/bevformer_base.py \
ckpts/bevformer_r101_dcn_24ep.pth \
--eval bbox如果看到mAP和NDS的输出结果,说明环境搭建成功!
Day 3-4:深入理解BEVFormer代码结构
代码阅读指南
BEVFormer的代码结构如下,按这个顺序阅读:
BEVFormer/
├── projects/configs/bevformer/
│ └── bevformer_base.py # ← 第1个读:配置文件,定义了所有超参数
├── projects/mmdet3d_plugin/
│ ├── bevformer/
│ │ ├── detectors/
│ │ │ └── bevformer.py # ← 第2个读:整体Pipeline,forward()入口
│ │ ├── modules/
│ │ │ ├── encoder.py # ← 第3个读:BEVFormerEncoder,核心!
│ │ │ ├── spatial_cross_attention.py # ← 第4个读:空间交叉注意力
│ │ │ ├── temporal_self_attention.py # ← 第5个读:时序自注意力
│ │ │ └── decoder.py # ← 第6个读:检测头
│ │ └── datasets/ # 数据加载你应该重点理解的三个函数
1. BEVFormerEncoder.forward() — 整个BEV特征生成的主循环
读这个函数时,关注它是怎么把多视角图像特征转换成BEV特征的。核心流程:初始化BEV Query → 逐层做空间交叉注意力 → 做时序自注意力 → 输出BEV特征。
2. SpatialCrossAttention.forward() — 多视角特征融合的核心
关注reference_points是怎么从BEV坐标投影到各个摄像头的像素坐标的。这里用到了相机内外参矩阵。
3. TemporalSelfAttention.forward() — 时序信息融合
关注它是怎么把上一帧的BEV特征warp(对齐)到当前帧的坐标系下的。这里用到了自车运动(ego motion)信息。
实操建议: 在这三个函数的入口和出口加
print(tensor.shape),跑一次推理,观察数据维度的变化。比如BEV Query从(1, 200*200, 256)经过空间交叉注意力后维度不变但数值变了——说明它从图像特征中"吸收"了信息。
Week 2:nuScenes数据集深度理解 + Waypoints规划
Day 5-6:nuScenes数据集实操
数据集结构详解
nuScenes是自动驾驶领域最重要的数据集,你后续复现的所有论文(UniAD、VAD、SparseDrive)都基于它。
# 用Python探索nuScenes数据集
from nuscenes.nuscenes import NuScenes
nusc = NuScenes(version='v1.0-mini', dataroot='./data/nuscenes', verbose=True)
# 查看一个场景
scene = nusc.scene[0]
print(f"场景名: {scene['name']}, 描述: {scene['description']}")
print(f"包含 {scene['nbr_samples']} 个关键帧")
# 查看一个样本(关键帧)
sample = nusc.get('sample', scene['first_sample_token'])
# 查看该样本的所有传感器数据
for sensor_channel, sd_token in sample['data'].items():
sd = nusc.get('sample_data', sd_token)
print(f" 传感器: {sensor_channel:25s} 文件: {sd['filename']}")
# 输出类似:
# 传感器: CAM_FRONT 文件: samples/CAM_FRONT/xxx.jpg
# 传感器: CAM_FRONT_LEFT 文件: samples/CAM_FRONT_LEFT/xxx.jpg
# 传感器: CAM_FRONT_RIGHT 文件: samples/CAM_FRONT_RIGHT/xxx.jpg
# 传感器: CAM_BACK 文件: samples/CAM_BACK/xxx.jpg
# 传感器: CAM_BACK_LEFT 文件: samples/CAM_BACK_LEFT/xxx.jpg
# 传感器: CAM_BACK_RIGHT 文件: samples/CAM_BACK_RIGHT/xxx.jpg
# 传感器: LIDAR_TOP 文件: samples/LIDAR_TOP/xxx.bin
获取3D标注和轨迹
import numpy as np
# 获取该帧的所有3D标注框
annotations = sample['anns']
for ann_token in annotations[:3]: # 看前3个
ann = nusc.get('sample_annotation', ann_token)
print(f" 类别: {ann['category_name']}")
print(f" 位置 (x,y,z): {ann['translation']}")
print(f" 尺寸 (w,l,h): {ann['size']}")
print(f" 可见度: {ann['visibility_token']}")
print()
# 获取自车轨迹(ego pose)
sample_data = nusc.get('sample_data', sample['data']['LIDAR_TOP'])
ego_pose = nusc.get('ego_pose', sample_data['ego_pose_token'])
print(f"自车位置: {ego_pose['translation']}")
print(f"自车朝向: {ego_pose['rotation']}") # 四元数可视化6个摄像头的图像
import matplotlib.pyplot as plt
from nuscenes.utils.data_classes import LidarPointCloud
from PIL import Image
fig, axes = plt.subplots(2, 3, figsize=(18, 8))
cam_channels = ['CAM_FRONT_LEFT', 'CAM_FRONT', 'CAM_FRONT_RIGHT',
'CAM_BACK_LEFT', 'CAM_BACK', 'CAM_BACK_RIGHT']
for ax, channel in zip(axes.flat, cam_channels):
sd_token = sample['data'][channel]
sd = nusc.get('sample_data', sd_token)
img = Image.open(f"./data/nuscenes/{sd['filename']}")
ax.imshow(img)
ax.set_title(channel, fontsize=10)
ax.axis('off')
plt.tight_layout()
plt.savefig('six_cameras.png', dpi=150)
print("已保存六个摄像头图像到 six_cameras.png")Day 7-8:从steer/throttle升级到Waypoints
为什么工业界都用Waypoints?
在第一阶段中,我们的模型直接预测steer和throttle。但这有严重问题:
- 不可解释: steer=0.3是什么意思?看不出车要去哪。
- 不稳定: 微小的steer预测误差会随时间累积,导致车越开越偏。
- 不灵活: 不同车速下,同样的steer对应完全不同的转弯半径。
Waypoints(路点)方案: 模型输出未来3秒内车辆应该经过的一系列坐标点(比如6个点,每0.5秒一个),然后用PID控制器跟踪这些点。
模型输出:[(0,0), (1.2, 0.1), (2.5, 0.3), (3.8, 0.8), (5.0, 1.5), (6.0, 2.5)]
含义: 现在 0.5秒后 1秒后 1.5秒后 2秒后 2.5秒后类比理解: 预测steer/throttle就像告诉司机"方向盘转30度、油门踩一半";预测waypoints就像告诉司机"沿着这条线开"。后者更直观、更容易纠错。
PID控制器:把Waypoints变成steer/throttle
class PIDController:
"""
PID控制器:根据当前位置和目标路点,计算steer和throttle
P(比例):偏差越大,纠正力度越大
I(积分):累积偏差,消除稳态误差
D(微分):预测偏差变化趋势,减少超调
"""
def __init__(self, kp=1.0, ki=0.1, kd=0.5):
self.kp, self.ki, self.kd = kp, ki, kd
self.error_sum = 0
self.prev_error = 0
def step(self, error, dt=0.05):
self.error_sum += error * dt
d_error = (error - self.prev_error) / dt
self.prev_error = error
return self.kp * error + self.ki * self.error_sum + self.kd * d_error
def waypoints_to_control(waypoints, current_speed):
"""
将waypoints转换为steer和throttle
waypoints: [(x1,y1), (x2,y2), ...] 在自车坐标系下
"""
# 取第2个路点作为近期目标(第1个太近了)
target_x, target_y = waypoints[1]
# 计算转向角:arctan(y/x)
# 自车坐标系中,x是前方,y是左方
steer_angle = np.arctan2(target_y, target_x)
steer = np.clip(steer_angle / np.pi * 2, -1, 1) # 归一化到[-1, 1]
# 计算目标速度:离目标越远,速度越快
target_speed = np.sqrt(target_x**2 + target_y**2) / 0.5 # 0.5秒到达
target_speed = min(target_speed, 8.0) # 限速8 m/s
# PID控制油门/刹车
speed_error = target_speed - current_speed
if speed_error > 0:
throttle = min(speed_error * 0.3, 1.0)
brake = 0
else:
throttle = 0
brake = min(-speed_error * 0.3, 1.0)
return steer, throttle, brakeWeek 3:复现VAD——真正的工业级端到端
Day 9-10:理解VAD架构
VAD是什么?为什么选VAD?
VAD(Vectorized Autonomous Driving)是华中科技大学和地平线联合提出的端到端自动驾驶方法(ICCV 2023)。它是UniAD之后最重要的工作之一,核心改进是用向量化表示替代了栅格化表示。
UniAD的做法(栅格化): VAD的做法(向量化):
把地图画成200×200的像素图 → 用折线/多边形表示车道线
把占据预测画成栅格图 → 用向量表示每个智能体的轨迹
计算量大、丢失结构信息 → 计算量小、保留实例信息类比理解: 栅格化就像用像素画画——你得一个点一个点地涂;向量化就像用CAD画图——你只需要画几条线段。后者信息密度更高、计算更快。
VAD的整体架构
6个摄像头图像
↓
ResNet-50 提取图像特征
↓
BEVFormer 生成BEV特征 (200×200×256)
↓
┌──────────────┬──────────────┐
│ Agent Query │ Map Query │ ← 向量化场景表示
│ (检测+跟踪) │ (车道线+区域) │
└──────┬───────┴──────┬───────┘
│ │
↓ ↓
Agent-Map 交互(Transformer交叉注意力)
│
↓
Motion Query → 预测每个Agent的未来轨迹
│
↓
Ego Planning Query → 规划自车轨迹(Waypoints输出)VAD vs UniAD 的关键区别
| 对比项 | UniAD | VAD |
|---|---|---|
| 地图表示 | 栅格化(语义分割图) | 向量化(折线段集合) |
| 运动预测 | 6个高斯混合模态 | 向量化轨迹 |
| 占据预测 | 有OccFormer模块 | 去掉了,用向量化替代 |
| 推理速度 | ~1.8 FPS | ~4.5 FPS(2.5倍提速) |
| 规划安全性 | 碰撞优化Loss | 向量化约束Loss |
Day 11-13:复现VAD
Step 1:克隆VAD代码
git clone https://github.com/hustvl/VAD.git
cd VADVAD的环境依赖和BEVFormer类似(都基于mmdetection3d),如果你已经搭好BEVFormer环境,大部分依赖可以复用。
Step 2:下载预训练权重并运行评估
# 下载VAD-Base预训练权重
mkdir ckpts && cd ckpts
# 从VAD的GitHub Release页面下载
wget https://github.com/hustvl/VAD/releases/download/v1.0/VAD_base.pth
cd ..
# 运行评估(用nuScenes Mini或Full数据集)
python tools/test.py \
projects/configs/VAD/VAD_base.py \
ckpts/VAD_base.pth \
--eval bboxStep 3:理解VAD的核心代码
VAD的代码结构:
VAD/
├── projects/configs/VAD/
│ └── VAD_base.py # 配置文件
├── projects/mmdet3d_plugin/VAD/
│ ├── VAD.py # ← 主模型,读这个!
│ ├── planner/
│ │ └── planning_head.py # ← 规划头,输出waypoints
│ ├── modules/
│ │ ├── encoder.py # BEV编码器(复用BEVFormer)
│ │ └── map_modules.py # ← 向量化地图模块
│ └── losses/
│ └── planning_loss.py # ← 规划损失函数重点阅读 planning_head.py:
# 伪代码:VAD规划头的核心逻辑
class PlanningHead:
def forward(self, bev_features, agent_queries, map_queries):
# 1. 初始化Ego Query
ego_query = self.ego_query_embedding # 可学习的自车查询向量
# 2. Ego Query与Agent/Map交互
ego_query = self.cross_attention(ego_query, agent_queries) # 看看周围有什么车
ego_query = self.cross_attention(ego_query, map_queries) # 看看路面情况
# 3. 输出未来6个waypoints
waypoints = self.mlp(ego_query) # (B, 6, 2) 6个点,每个点(x, y)
return waypointsStep 4:训练VAD(用Mini数据集快速验证)
# 修改配置文件中的数据集路径和batch_size
# 在VAD_base.py中找到这些参数并修改:
# data_root = './data/nuscenes/'
# samples_per_gpu = 1 # 单卡3090建议设为1
# 开始训练
python tools/train.py \
projects/configs/VAD/VAD_base.py \
--gpu-ids 0⚠️ 显存注意: VAD-Base在RTX 3090上需要约20GB显存(batch_size=1)。如果OOM,可以尝试VAD-Tiny配置,或者减小BEV分辨率。
Week 4:从VAD到工业实践
Day 14-15:VAD的损失函数深度理解
VAD的训练涉及多个损失函数的加权求和,理解它们对于调参至关重要:
total_loss = (
w1 * detection_loss # 3D目标检测Loss(分类+回归)
+ w2 * map_loss # 向量化地图Loss(车道线检测)
+ w3 * motion_loss # 运动预测Loss(ADE/FDE)
+ w4 * planning_loss # 规划Loss(模仿学习L1 Loss)
+ w5 * collision_loss # 碰撞约束Loss(安全性)
)| 损失 | 含义 | 如果这个Loss不降 |
|---|---|---|
| detection_loss | 3D检测框的位置和类别 | BEV特征质量差,检查backbone |
| map_loss | 车道线的位置和类型 | Map Query数量或BEV分辨率不够 |
| motion_loss | 预测轨迹和真实轨迹的距离 | Agent-Map交互没学好 |
| planning_loss | 规划轨迹和专家轨迹的距离 | 模仿学习的核心,确保数据质量 |
| collision_loss | 规划轨迹是否与障碍物碰撞 | 安全约束,权重不能太大否则车不敢动 |
Day 16-17:VAD评测指标详解
感知指标
- mAP(mean Average Precision): 3D目标检测的精度。越高越好,VAD-Base约0.32。
- NDS(NuScenes Detection Score): 综合指标,包含mAP和位置/尺寸/朝向/速度误差。
规划指标
- L2 Error(位移误差): 预测轨迹和真实轨迹在1s/2s/3s处的L2距离。单位是米。
- Collision Rate(碰撞率): 预测轨迹是否会和其他障碍物碰撞。越低越好。
- ADE(Average Displacement Error): 所有时间步的平均位移误差。
- FDE(Final Displacement Error): 最后一个时间步的位移误差。
# 评测代码示例
def compute_l2_error(pred_waypoints, gt_waypoints):
"""
pred_waypoints: (6, 2) 预测的6个路点
gt_waypoints: (6, 2) 真实的6个路点
"""
errors = np.sqrt(np.sum((pred_waypoints - gt_waypoints)**2, axis=1))
l2_1s = errors[1] # 第2个点(1秒后)
l2_2s = errors[3] # 第4个点(2秒后)
l2_3s = errors[5] # 第6个点(3秒后)
return l2_1s, l2_2s, l2_3sDay 18-19:VAD可视化 + 消融实验
可视化BEV感知结果
# 在推理后可视化BEV空间中的检测结果
import matplotlib.pyplot as plt
import numpy as np
def visualize_bev_results(pred_boxes, pred_map, ego_trajectory):
"""
pred_boxes: 检测到的3D框 (N, 7) [x,y,z,w,l,h,yaw]
pred_map: 预测的车道线 (M, K, 2) M条线,每条K个点
ego_trajectory: 规划轨迹 (6, 2)
"""
fig, ax = plt.subplots(figsize=(10, 10))
# 画检测框
for box in pred_boxes:
x, y, _, w, l, _, yaw = box
rect = plt.Rectangle((x-w/2, y-l/2), w, l, angle=np.degrees(yaw),
fill=False, color='red', linewidth=2)
ax.add_patch(rect)
# 画车道线
for lane in pred_map:
ax.plot(lane[:, 0], lane[:, 1], 'g-', linewidth=1.5)
# 画规划轨迹
ax.plot(ego_trajectory[:, 0], ego_trajectory[:, 1],
'b-o', linewidth=3, markersize=8, label='Planning')
# 画自车
ax.plot(0, 0, 'k^', markersize=15, label='Ego')
ax.set_xlim(-30, 30)
ax.set_ylim(-10, 50)
ax.set_aspect('equal')
ax.legend()
ax.set_title('BEV Visualization')
plt.savefig('bev_visualization.png', dpi=150)消融实验:理解每个模块的贡献
在VAD配置文件中,你可以逐个关闭模块来观察性能变化:
# 实验1:去掉Map模块
use_map = False # 在配置文件中修改
# 实验2:去掉Agent-Map交互
use_agent_map_interaction = False
# 实验3:去掉碰撞约束Loss
collision_loss_weight = 0.0做这些消融实验能帮你深入理解:为什么知道车道线很重要?为什么需要Agent-Map交互?为什么碰撞约束不能少?
Day 20-21:连接CARLA——在仿真中跑VAD
把VAD接入CARLA做闭环测试
VAD官方已经提供了CARLA实现(通过Bench2Drive项目):
# 克隆Bench2Drive
git clone https://github.com/Thinklab-SJTU/Bench2DriveZoo.git
cd Bench2DriveZoo
# 按照README配置环境和CARLA
# Bench2Drive提供了VAD在CARLA中的闭环评测脚本这一步将你在第一阶段学到的CARLA闭环测试技能,和第二阶段学到的VAD模型结合起来,形成完整的"训练→评测→闭环"pipeline。
总结:第二阶段学到了什么?
| 周次 | 内容 | 掌握的核心能力 |
|---|---|---|
| Week 1 | BEVFormer推理 + 代码阅读 | 理解BEV感知原理,能跑通BEVFormer |
| Week 2 | nuScenes数据集 + Waypoints | 掌握数据集操作,理解waypoints规划 |
| Week 3 | VAD复现 | 端到端架构理解,能跑通训练和评测 |
| Week 4 | 可视化 + 消融 + CARLA闭环 | 工程实践能力,面试可展示的项目 |
下一步:第三阶段预告
第三阶段将进入当前最前沿的方向:
- SparseDrive — 稀疏表示的一段式端到端(去掉BEV Dense特征)
- DiffusionDrive / GoalFlow — 用扩散模型做多模态轨迹规划
- NAVSIM评测 — 当前行业标准的端到端评测基准
- VLA入门 — 用Qwen2.5-VL做视觉语言动作模型
掌握了BEV + VAD之后,这些进阶方向都是在同一个框架上的"模块替换",学习曲线会平缓得多。
相关文章:
GITHUB | BEVFormer: a Cutting-edge Baseline for Camera-based Detection
BEVFormer 源码解读及本地环境配置
自动驾驶BEV感知有哪些让人眼前一亮的新方法?
为者常成,行者常至
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)



