
自动驾驶-第三阶段-一段式端到端 + 扩散模型规划
第三阶段:一段式端到端 + 扩散模型规划
从两段式到一段式,从单轨迹回归到多模态生成
前置要求: 完成第二阶段(BEV感知 + VAD复现)
时间规划: 3周(每天2-4小时)
硬件要求: RTX 3090 24GB
本阶段你将掌握的核心技术
第一阶段学的: 单摄像头 → ResNet → steer/throttle(最简模仿学习)
第二阶段学的: 6摄像头 → BEV → 向量化表示 → waypoints(VAD,两段式)
本阶段要学的: 6摄像头 → 稀疏表示 → 扩散模型生成多条轨迹(一段式)
↑ 这就是当前工业界的主流方案Week 1:从两段式到一段式——SparseDrive
Day 1:理解"一段式"和"两段式"的区别
什么是两段式?什么是一段式?
┌─ 两段式(UniAD、VAD)─────────────────────────────────────────┐
│ │
│ 第一阶段训练:感知模块(BEVFormer + 检测 + 建图) │
│ ↓ 冻结权重 │
│ 第二阶段训练:预测 + 规划模块 │
│ │
│ 问题:感知的错误无法被规划阶段纠正(误差单向传播) │
└────────────────────────────────────────────────────────────────┘
┌─ 一段式(SparseDrive、DiffusionDrive)────────────────────────┐
│ │
│ 所有模块同时训练:感知 + 预测 + 规划 端到端联合优化 │
│ │
│ 好处:规划的loss可以反向传播到感知,让感知"学会"关注对规划 │
│ 有用的信息(比如更关注前方即将变道的车,而不是路边的树) │
└────────────────────────────────────────────────────────────────┘类比理解:
两段式就像高考分两次考——先考语数外(感知),成绩定了就不能改,然后用这个成绩去选专业(规划)。如果语文考砸了,选专业时也没办法补救。
一段式就像综合评价——所有科目一起考、一起打分,语文不好可以用数学补,最终看总分。系统能自动找到最优的科目配比。
什么是"稀疏表示"?为什么比BEV Dense更好?
在第二阶段中,BEVFormer生成的是一个200×200×256的Dense BEV特征图——这意味着即使某个位置什么都没有(空地),也要计算和存储特征。这很浪费。
Dense BEV(BEVFormer/VAD): Sparse表示(SparseDrive):
┌──────────────────────┐ 只关注有意义的位置:
│██░░░░██░░░░░░░░░░░░░│ ● 车1 → 一个Query向量
│░░░░░░░░██░░░░░░░░░░░│ ● 车2 → 一个Query向量
│░░░░░░░░░░░░░░░░░░░░░│ ● 行人 → 一个Query向量
│░░░░░░░░░░░░░░░░░░░░░│ ● 车道线1 → 一组Query向量
│░░░░░░██░░░░░░░░░░░░░│
│░░░░░░░░░░░░░░░░░░░░░│ 总共可能只有100-300个Query
└──────────────────────┘ 而不是200×200=40000个像素
200×200 = 40000个位置都要计算
大部分是空的(░),浪费算力类比理解:
Dense BEV就像拍一张超大的全景照片,然后在照片的每个像素上都标注"这里有什么"——绝大部分像素标注的都是"空地"。
Sparse表示就像记笔记——只记录有意义的信息:"路口北边有一辆白色SUV在等红灯,距我30米"。信息量更小但更精准。
SparseDrive正是用这种稀疏表示,将检测、跟踪、建图、预测、规划统一在一个框架里,实现了一段式端到端训练。
Day 2-3:SparseDrive架构详解与代码复现
SparseDrive的整体架构
6个摄像头图像
↓
ResNet-50 提取多尺度图像特征
↓
┌─────────────────────────────────────────────────┐
│ 对称稀疏感知(Symmetric Sparse Perception)│
│ │
│ Detection Query ←→ 图像特征 → 检测3D目标 │
│ Map Query ←→ 图像特征 → 在线建图 │
│ │
│ 两者共享相同的注意力结构(所以叫"对称") │
└─────────────────┬───────────────────────────────┘
↓
┌─────────────────────────────────────────────────┐
│ 并行运动规划器(Parallel Motion Planner) │
│ │
│ Motion Query → 预测每个Agent未来轨迹 │
│ Planning Query → 生成自车多条候选轨迹 │
│ Collision-Aware Rescore → 选出最安全的那条 │
│ │
│ 预测和规划是并行的!不是串行的! │
└─────────────────────────────────────────────────┘
↓
输出:自车规划轨迹(waypoints)关键概念:Instance Memory Queue(实例记忆队列)
SparseDrive为每个被跟踪的目标维护一个"记忆"——过去几帧它在哪里、长什么样。这就像你开车时脑子里记着"右边那辆红色宝马刚才在加速"。这个记忆让模型不需要每一帧都从零开始检测,大大提高了效率和时序一致性。
环境搭建与代码运行
# 克隆SparseDrive
git clone https://github.com/swc-17/SparseDrive.git
cd SparseDrive
# 创建环境
conda create -n sparsedrive python=3.8 -y
conda activate sparsedrive
# 安装依赖
pip install torch==1.13.0+cu116 torchvision==0.14.0+cu116 \
--extra-index-url https://download.pytorch.org/whl/cu116
pip install -r requirement.txt
# 编译自定义算子
cd projects/mmdet3d_plugin/ops
python setup.py develop
cd ../../../
# 数据准备(同VAD,使用nuScenes)
ln -s /path/to/nuscenes ./data/nuscenes
# 生成标注pkl文件
python tools/data_converter/nuscenes_converter.py \
--root-path ./data/nuscenes \
--out-dir ./data/infos \
--version v1.0-mini下载预训练权重并运行评估
# 从SparseDrive的GitHub Releases下载预训练权重
# 放到 ckpts/ 目录下
# 运行评估
python tools/test.py \
projects/configs/sparsedrive_small_stage2.py \
ckpts/sparsedrive_stage2.pth \
--eval bboxDay 4-5:SparseDrive代码深度阅读
重点阅读三个文件
文件1:projects/configs/sparsedrive_small_stage2.py
这是配置文件,定义了整个模型的结构。重点关注:
# 理解这些关键参数的含义:
num_det_query = 900 # 检测用的Query数量(最多检测900个目标)
num_map_query = 200 # 地图用的Query数量
num_motion_mode = 6 # 每个Agent预测6种可能的运动模式
plan_num_future = 6 # 规划未来6个时间步的轨迹
planning_num_anchor = 1024 # 规划用的锚点轨迹数量概念解释:Motion Mode(运动模式)
一辆车在路口可能直行、左转或右转——这就是3种"运动模式"。MotionFormer为每个Agent预测K种可能的模式,每种模式对应一条轨迹和一个概率。这就是"多模态预测"——不是预测一条确定的轨迹,而是预测多种可能性。
文件2:projects/mmdet3d_plugin/models/sparsedrive.py
这是主模型文件。关注forward_train()函数中各个模块的调用顺序:
# 伪代码
def forward_train(self, images, ...):
# 1. 图像特征提取
img_feats = self.backbone(images) # ResNet-50
img_feats = self.neck(img_feats) # FPN多尺度特征
# 2. 稀疏感知(检测 + 建图)
det_output, map_output = self.sparse_perception(
img_feats, det_query, map_query
)
# 3. 并行运动规划
motion_output, plan_output = self.motion_planner(
det_output, map_output, ego_status
)
# 4. 计算所有损失
losses = self.compute_losses(det_output, map_output,
motion_output, plan_output)
return losses文件3:projects/mmdet3d_plugin/models/planning_head.py
这是规划头。关注它如何从1024条候选轨迹中选出最优的:
# 伪代码:分层规划选择(Hierarchical Planning Selection)
def select_best_trajectory(self, candidate_trajectories, scene_features):
# Step 1: 用MLP为每条候选轨迹打分
scores = self.scoring_mlp(candidate_trajectories, scene_features)
# Step 2: 碰撞感知重打分
for i, traj in enumerate(candidate_trajectories):
if self.check_collision(traj, predicted_agent_trajectories):
scores[i] *= 0.1 # 大幅降低碰撞轨迹的分数
# Step 3: 选分数最高的
best_idx = scores.argmax()
return candidate_trajectories[best_idx]概念解释:为什么用1024条候选轨迹?
这些候选轨迹是从训练数据中用K-Means聚类预先提取的"典型轨迹模式"。比如直行、左转30度、右转60度、急刹车等。模型不是从零开始生成轨迹,而是从这1024种"模板"中选一条最合适的并微调。这就像你学开车时,教练教你"这种路口一般这样过"——你不需要每次都重新发明开车方法。
Week 2:NAVSIM评测基准——行业标准的竞技场
Day 6-7:理解NAVSIM
NAVSIM是什么?为什么它这么重要?
NAVSIM是由Tübingen大学、NVIDIA、OpenDriveLab等联合推出的端到端自动驾驶评测基准(NeurIPS 2024)。它解决了一个行业痛点:
之前的评测方式:
开环评测(nuScenes L2 Error) 闭环评测(CARLA)
├── 简单快速 ├── 最真实
├── 但不反映真实驾驶能力 ├── 但计算量巨大
└── 一个"瞎子"模型也能拿低L2 └── 且仿真和真实有差距
NAVSIM的方案:伪闭环评测(Pseudo-Simulation)
├── 用真实数据(来自nuPlan数据集的120小时驾驶日志)
├── 在BEV抽象空间中展开短期模拟(4秒)
├── 计算类似闭环的指标(碰撞、进度、舒适度等)
├── 但不需要真正的交互式仿真
└── 结果:计算量只有闭环的1/6,但相关性很高!类比理解:
开环评测就像"看录像判断你的开车水平"——给你看一段路况视频,让你说"接下来方向盘怎么打",但你的回答不会影响视频播放。
闭环评测就像"真的让你上路"——你打方向盘会真的让车转弯,然后新的路况出现。
NAVSIM就像"桌面推演"——在地图上用小模型推演你的驾驶决策在接下来4秒会怎样,有没有撞车、有没有偏离车道。比看录像更真实,比真上路更高效。
NAVSIM的核心指标:PDMS(Planning-oriented Driving Metric Score)
PDMS是一个综合评分(0-100),由多个子指标加权组成:
PDMS = EP × (w1×NC + w2×DAC + w3×TTC + w4×Comfort + ...)
EP = Ego Progress 自车行驶进度(你到底有没有在往前开?)
NC = No Collision 没有碰撞
DAC = Drivable Area 是否在可行驶区域内
TTC = Time to Collision 距碰撞的时间裕度
Comfort = 舒适度 加速度/转向是否平滑
EP是乘法关系——如果你根本不动(EP=0),其他再好也是0分!为什么EP很重要?
以前很多模型学到了一个"作弊"策略:原地不动就不会碰撞。在nuScenes的L2评测里,这种"怯场"模型反而能得到不错的分数。但在NAVSIM中,EP=0意味着总分=0——你必须往前开才能得分。这迫使模型学会真正的驾驶决策,而不是"苟住不动"。
Day 8-9:跑通NAVSIM Baseline
环境搭建
# 克隆NAVSIM
git clone https://github.com/autonomousvision/navsim.git
cd navsim
# 创建环境
conda create -n navsim python=3.9 -y
conda activate navsim
# 安装依赖
pip install -e .
# 下载数据(NAVSIM使用OpenScene/nuPlan数据的子集)
# 按照 docs/install.md 中的说明从HuggingFace下载
# 大约需要50-100GB空间运行Baseline模型
NAVSIM提供了几个baseline,从简单到复杂:
# Baseline 1: EgoStatusMLP("瞎子"baseline)
# 只看自车速度/加速度,完全不看摄像头
# 用来理解"不看路也能得多少分"
python navsim/run.py \
agent=ego_status_mlp \
split=navtest
# Baseline 2: TransFuser(图像+LiDAR融合)
# 经典的端到端方法,使用CNN+Transformer
python navsim/run.py \
agent=transfuser \
split=navtest惊人的发现: EgoStatusMLP这个"瞎子"模型在未过滤的数据上能拿到约91%的PDMS!这说明大多数驾驶场景都是"无聊"的直行——所以NAVSIM会对数据做过滤(filtering),只保留挑战性场景(急转弯、避障、路口等)。过滤后的数据上,"瞎子"模型的分数会大幅下降。
创建你自己的Agent
NAVSIM的Agent接口非常简洁:
from navsim.agents.abstract_agent import AbstractAgent
from navsim.common.dataclasses import Trajectory, TrajectorySampling
class MyAgent(AbstractAgent):
"""你的自定义端到端驾驶Agent"""
def name(self) -> str:
return "my_first_agent"
def initialize(self) -> None:
"""加载模型权重"""
self.model = load_your_model()
def compute_trajectory(self, features) -> Trajectory:
"""
核心方法:给定传感器输入,输出规划轨迹
features包含:
- features.camera_images: 多视角摄像头图像
- features.ego_status: 自车速度、加速度
- features.driving_command: 导航指令(直行/左转/右转)
需要输出:
- Trajectory: 未来4秒、10Hz的BEV位姿序列(40个点)
"""
# 你的模型推理逻辑
predicted_waypoints = self.model(
features.camera_images,
features.ego_status,
features.driving_command
)
return Trajectory(
poses=predicted_waypoints, # (40, 3) 每个点有x, y, heading
sampling=TrajectorySampling(
time_horizon=4.0, # 4秒
interval_length=0.1 # 10Hz
)
)实操建议: 先把EgoStatusMLP跑通,看看它的PDMS分数。然后试着写一个简单的改进版:在EgoStatusMLP的基础上加入前视摄像头图像(用第一阶段学的ResNet提特征),看PDMS能提高多少。这个"最小改进实验"能帮你快速理解NAVSIM的评测流程。
Week 3:扩散模型做规划——DiffusionDrive
Day 10-11:理解扩散模型的核心思想
什么是扩散模型?
扩散模型是一种生成模型——它能学会"创造"数据,而不只是"分类"数据。
扩散模型的两个过程:
正向过程(加噪声):逐步往干净数据上加随机噪声,直到变成纯噪声
清晰轨迹 → 稍微模糊 → 很模糊 → 完全看不出 → 纯随机噪声
x₀ → x₁ → x₂ → ... → xₜ
反向过程(去噪声):学习从噪声中恢复出干净数据
纯随机噪声 → 有点形状 → 越来越清晰 → 干净轨迹
xₜ → xₜ₋₁ → ... → x₀类比理解(墨水类比):
想象你在白纸上画了一条漂亮的行车轨迹线(x₀),然后往上面不断泼水,墨迹越来越模糊(x₁, x₂...),最终完全变成均匀的灰色(xₜ,纯噪声)。
扩散模型要学的就是"逆向"这个过程——给你一张均匀灰色的纸,它能一步步把轨迹线"恢复"出来。关键是:这个恢复过程是有条件的——给不同的路况条件,它会恢复出不同的轨迹(直行、转弯、避障等)。
为什么用扩散模型做规划?——Mode Collapse问题
第一阶段和第二阶段中,我们用的都是回归方法(MSE Loss),让模型预测一条轨迹。但这有一个致命问题:
场景:你在路口,可以直行也可以右转,两种都是合理的。
训练数据中:
- 50%的情况人类选择了直行
- 50%的情况人类选择了右转
MSE回归模型的学习结果:
- 预测一条"平均轨迹"——既不直行也不右转,而是斜着冲向路中间!
这就是 Mode Collapse(模式坍缩)——模型把多种合理选择"平均"成了
一种不合理的选择。┌─ MSE回归 ──────────┐ ┌─ 扩散模型 ──────────────┐
│ │ │ │
│ ╱ 直行(GT) │ │ ╱ 直行 (概率50%) │
│ ╱ │ │ ╱ │
│ ●──── 预测(平均) │ │ ● │
│ ╲ │ │ ╲ │
│ ╲ 右转(GT) │ │ ╲ 右转 (概率50%) │
│ │ │ │
│ ❌ 预测出不合理轨迹 │ │ ✅ 生成两种合理轨迹 │
└─────────────────────┘ └──────────────────────────┘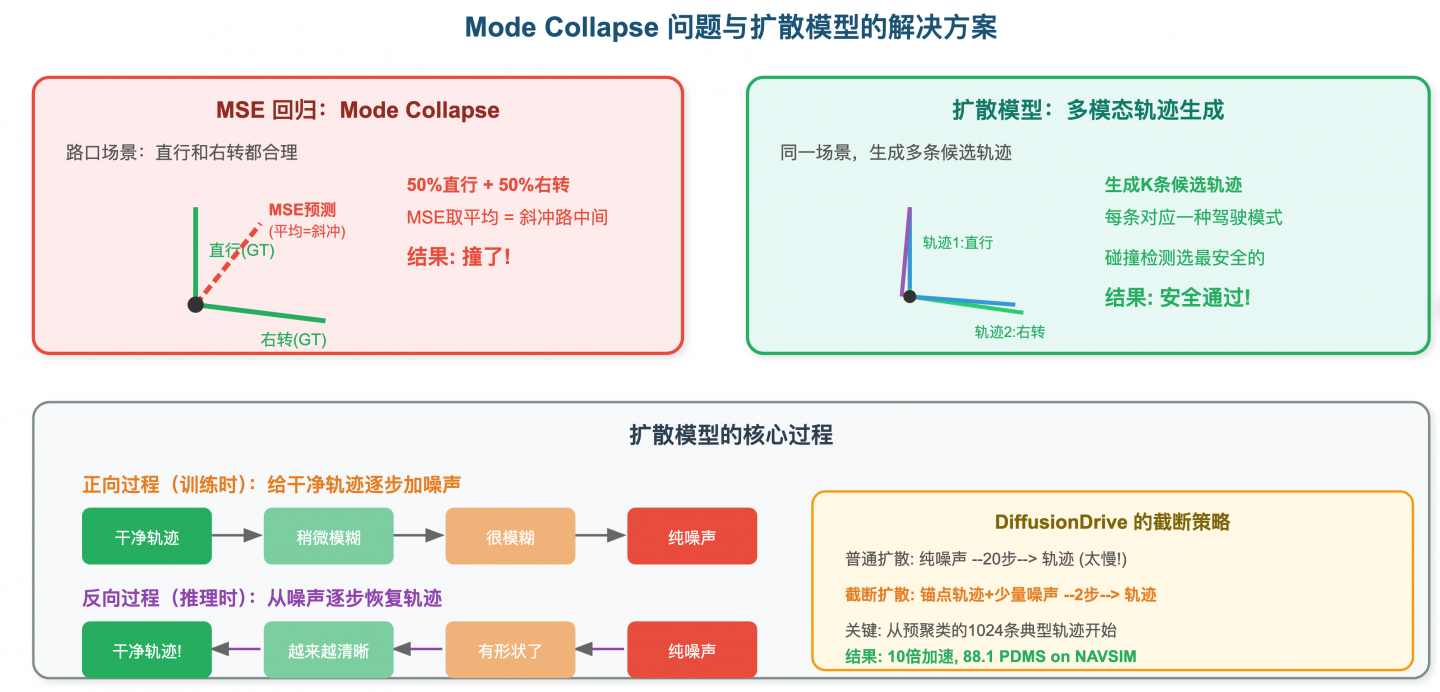
扩散模型能生成多条轨迹,每条对应一种合理的驾驶模式——直行的概率50%、右转的概率50%。然后用碰撞检测等安全约束从中选出最优的那条。
Day 12-13:DiffusionDrive详解——截断扩散策略
DiffusionDrive的核心创新
普通扩散模型需要20-50步去噪,太慢了(自动驾驶要求实时)。DiffusionDrive的核心创新是截断扩散(Truncated Diffusion):
普通扩散模型(20步去噪,太慢):
纯噪声 →→→→→→→→→→→→→→→→→→→→ 轨迹
xₜ x₀
20步
DiffusionDrive(2步去噪,实时!):
锚点轨迹 + 少量噪声 →→ 轨迹
x₂ x₀
只需2步!关键洞察: 人类的驾驶行为是有规律的——绝大多数情况下,你要么直行、要么转弯、要么换道。这些"典型行为"可以预先从数据中提取出来作为"锚点"(Anchor)。模型不需要从纯噪声开始生成轨迹,只需要从最接近的锚点开始,做少量调整即可。
类比理解: 普通扩散模型就像用粘土从零开始捏一辆车——需要很多步骤。DiffusionDrive就像拿一个已有的模型车做微调——换个颜色、调整一下轮子角度,两步就搞定了。
DiffusionDrive的完整架构
6个摄像头图像 + LiDAR BEV
↓
Transfuser Backbone(图像+LiDAR特征融合)
↓
场景特征 (Scene Context Features)
↓
┌────────────────────────────────────────┐
│ 截断扩散解码器 │
│ │
│ 1. 从K个锚点轨迹中采样 │
│ 2. 加少量噪声 → 得到初始噪声轨迹 │
│ 3. 级联去噪(2步): │
│ └→ 第1步:粗去噪 + 场景特征交互 │
│ └→ 第2步:精去噪 + 碰撞感知调整 │
│ 4. 输出K条候选轨迹 + 置信度分数 │
│ │
│ 选分数最高的轨迹作为最终输出 │
└────────────────────────────────────────┘
↓
最优规划轨迹(waypoints)跑通DiffusionDrive
# 克隆DiffusionDrive
git clone https://github.com/hustvl/DiffusionDrive.git
cd DiffusionDrive
# DiffusionDrive提供了NAVSIM和nuScenes两个版本
# 推荐先跑NAVSIM版本(main分支)
# 安装依赖(参考README)
pip install -r requirements.txt
# 下载预训练权重
# 从GitHub Releases下载
# 在NAVSIM上评测
python run_navsim.py \
agent=diffusion_drive \
split=navtestDay 14:实操——自己搭建一个简化版扩散规划器
为了真正理解扩散模型如何生成轨迹,我们来写一个最简单的2D轨迹扩散模型:
"""
mini_diffusion_planner.py
一个最简化的扩散模型轨迹生成器
目的:帮你理解扩散模型的核心数学,而不是直接用别人的代码
"""
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
# ===== 1. 定义噪声调度 =====
def get_noise_schedule(T=20, beta_start=1e-4, beta_end=0.02):
"""
线性噪声调度:随着时间步增加,噪声越来越大
T: 总时间步数(这里用20步,比DiffusionDrive的2步多,便于理解)
beta_t: 每一步添加的噪声量
alpha_t: 1 - beta_t,表示保留的信号量
alpha_bar_t: 所有alpha的累积乘积,表示从x₀到xₜ总共保留了多少信号
"""
betas = torch.linspace(beta_start, beta_end, T)
alphas = 1 - betas
alpha_bars = torch.cumprod(alphas, dim=0)
return betas, alphas, alpha_bars
# ===== 2. 正向过程:给轨迹加噪声 =====
def forward_diffusion(x0, t, alpha_bars):
"""
一步到位地给x0加噪声到第t步
公式:x_t = sqrt(alpha_bar_t) * x_0 + sqrt(1 - alpha_bar_t) * noise
直觉:alpha_bar_t越小(t越大),噪声成分越大,信号成分越小
"""
noise = torch.randn_like(x0)
alpha_bar_t = alpha_bars[t].view(-1, 1, 1) # (B, 1, 1)
x_t = torch.sqrt(alpha_bar_t) * x0 + torch.sqrt(1 - alpha_bar_t) * noise
return x_t, noise
# ===== 3. 去噪网络:学习预测噪声 =====
class NoisePredictor(nn.Module):
"""
输入:带噪声的轨迹 x_t + 时间步 t + 场景条件 c
输出:预测的噪声 epsilon
这是一个非常简化的版本。真正的DiffusionDrive用的是
级联Transformer解码器。
"""
def __init__(self, traj_dim=12, hidden_dim=128, condition_dim=32):
super().__init__()
# 时间编码:把离散的时间步t编码成向量
self.time_embed = nn.Sequential(
nn.Embedding(100, hidden_dim),
nn.SiLU(),
nn.Linear(hidden_dim, hidden_dim)
)
# 条件编码:场景信息(简化版只用自车速度)
self.cond_embed = nn.Linear(condition_dim, hidden_dim)
# 主网络
self.net = nn.Sequential(
nn.Linear(traj_dim + hidden_dim * 2, hidden_dim),
nn.SiLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.SiLU(),
nn.Linear(hidden_dim, traj_dim) # 输出维度和输入轨迹一样
)
def forward(self, x_t, t, condition):
"""
x_t: (B, 6, 2) 带噪声的轨迹(6个点,每个点xy)
t: (B,) 当前时间步
condition: (B, 32) 场景条件
"""
B = x_t.shape[0]
x_flat = x_t.view(B, -1) # (B, 12)
t_emb = self.time_embed(t) # (B, 128)
c_emb = self.cond_embed(condition) # (B, 128)
inp = torch.cat([x_flat, t_emb, c_emb], dim=1) # (B, 12+128+128)
noise_pred = self.net(inp) # (B, 12)
return noise_pred.view(B, 6, 2) # (B, 6, 2)
# ===== 4. 训练循环 =====
def train_diffusion(model, trajectories, conditions, epochs=500):
"""
trajectories: (N, 6, 2) 真实的驾驶轨迹数据
conditions: (N, 32) 对应的场景条件
"""
T = 20
_, _, alpha_bars = get_noise_schedule(T)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
for epoch in range(epochs):
# 随机选一批数据
idx = torch.randint(0, len(trajectories), (64,))
x0 = trajectories[idx] # (64, 6, 2)
cond = conditions[idx] # (64, 32)
# 随机选一个时间步
t = torch.randint(0, T, (64,))
# 加噪声
x_t, true_noise = forward_diffusion(x0, t, alpha_bars)
# 预测噪声
pred_noise = model(x_t, t, cond)
# Loss:预测的噪声和真实噪声之间的MSE
loss = nn.MSELoss()(pred_noise, true_noise)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0:
print(f"Epoch {epoch}, Loss: {loss.item():.4f}")
# ===== 5. 反向采样:从噪声生成轨迹 =====
@torch.no_grad()
def sample_trajectory(model, condition, num_samples=10):
"""
给定场景条件,生成多条候选轨迹
这就是扩散模型的"多模态"能力:
同一个条件下,每次采样都会生成不同的合理轨迹
"""
T = 20
betas, alphas, alpha_bars = get_noise_schedule(T)
# 从纯噪声开始
x = torch.randn(num_samples, 6, 2) # (10, 6, 2) 10条轨迹
cond = condition.unsqueeze(0).expand(num_samples, -1) # (10, 32)
# 逐步去噪
for t in reversed(range(T)):
t_tensor = torch.full((num_samples,), t, dtype=torch.long)
# 预测噪声
pred_noise = model(x, t_tensor, cond)
# 去噪一步(DDPM采样公式)
alpha_t = alphas[t]
alpha_bar_t = alpha_bars[t]
x = (1 / torch.sqrt(alpha_t)) * (
x - (betas[t] / torch.sqrt(1 - alpha_bar_t)) * pred_noise
)
# 除了最后一步,都要加一点噪声(保持随机性)
if t > 0:
x += torch.sqrt(betas[t]) * torch.randn_like(x)
return x # (10, 6, 2) 10条候选轨迹运行这个脚本后,你应该做什么?
- 用第一阶段在CARLA中采集的数据(轨迹坐标)作为训练数据
- 训练完后,给同一个场景条件多次采样,观察生成的10条轨迹是否呈现多样性
- 可视化这些轨迹——你应该能看到直行、微左转、微右转等不同模式
- 把最好的轨迹(比如离真实轨迹最近的)作为规划输出
Day 15:Flow Matching vs DDPM
什么是Flow Matching?
GoalFlow(CVPR 2025,地平线)使用的不是DDPM,而是Flow Matching——一种更新、更高效的生成方法。
DDPM(DiffusionDrive用的):
- 加噪声过程是随机的马尔可夫链
- 去噪需要多步迭代
- 数学上:学习预测噪声 ε
Flow Matching(GoalFlow用的):
- 加噪声过程是确定性的直线插值
- 理论上1步就能生成
- 数学上:学习预测速度场 v
直觉区别:
DDPM像是在迷宫里随机走,需要很多步才能走出来
Flow Matching像是画一条直线连接起点和终点,一步到位对你面试的意义: 面试官经常问"DDPM和Flow Matching的区别是什么?"。答出"DDPM学预测噪声ε,Flow Matching学预测速度场v;Flow Matching的采样路径是直线,训练更稳定,采样更高效"就够了。
总结与下一步
第三阶段学到了什么?
| 周次 | 内容 | 核心概念 |
|---|---|---|
| Week 1 | SparseDrive | 一段式vs两段式、稀疏表示、并行规划 |
| Week 2 | NAVSIM | 伪闭环评测、PDMS指标、创建Agent |
| Week 3 | DiffusionDrive | 扩散模型、Mode Collapse、截断扩散、Flow Matching |
你现在的技术栈
第一阶段 ✅ CARLA仿真 + 简单模仿学习 + 闭环测试
第二阶段 ✅ BEV感知 + VAD端到端 + nuScenes评测
第三阶段 ✅ 一段式端到端 + 扩散模型规划 + NAVSIM评测
第四阶段 → VLA + 强化学习 + 面试准备(下一步!)面试中你可以讲的项目经历
到这里你已经有一个完整的故事线可以讲了:
"我从CARLA仿真入手搭建了端到端自动驾驶的闭环pipeline,然后在nuScenes上复现了BEVFormer和VAD,理解了从BEV Dense到Sparse表示的演进。接着在NAVSIM基准上实现了基于扩散模型的多模态轨迹规划,理解了为什么DiffusionDrive的截断扩散策略能在只用2步去噪的情况下达到88.1 PDMS。"
这个叙事覆盖了感知→预测→规划的完整技术栈,且每一步都有代码实现和评测结果支撑,在面试中非常有说服力。
第四阶段预告:VLA + 强化学习
下一阶段将进入当前最前沿且招聘需求最旺盛的方向:
- ORION(小米开源VLA)推理与评测
- Qwen2.5-VL 做驾驶场景理解
- 多层次CoT SFT(链式思维监督微调)
- GRPO/RLHF 强化学习微调驾驶策略
- 模型部署(TensorRT加速、ONNX导出)
为者常成,行者常至
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)



