
从零到端到端自动驾驶实战-第三章-CARLA 仿真与模仿学习
一、启动Carla环境
carla 安装,请参考之前的博文;
(base) lionsking@ai-dev:~$ conda env list
# conda environments:
#
# * -> active
# + -> frozen
base * /home/lionsking/miniconda3
bevformer /home/lionsking/miniconda3/envs/bevformer
carla /home/lionsking/miniconda3/envs/carla
uniad2.0 /home/lionsking/miniconda3/envs/uniad2.0
(base) lionsking@ai-dev:~$ conda activate carla
(carla) lionsking@ai-dev:~$ cd /home/lionsking/carla
(carla) lionsking@ai-dev:~/carla$ ./CarlaUE4.sh -windowed -ResX=1280 -ResY=720 -quality-level=Epic
4.26.2-0+++UE4+Release-4.26 522 0
Disabling core dumps.
你的第一个CARLA脚本:生成一辆车并让它自动开
01_spawn_vehicle.py
import carla, random, time
# 连接到CARLA服务端
client = carla.Client('localhost', 2000)
client.set_timeout(10.0)
world = client.get_world()
#从蓝图库中找到Tesla
bp_lib = world.get_blueprint_library()
vehicle_bp = bp_lib.filter('vehicle.tesla.model3')[0]
#随机选一个出生点
spawn_point=random.choice(world.get_map().get_spawn_points())
#生成车辆
vehicle=world.spawn_actor(vehicle_bp,spawn_point)
print(f'✅车辆已生成: {vehicle.type_id}')
#开启自动驾驶(CARLA内置的规则引擎,不是神经网络)
vehicle.set_autopilot(True)
print('✅Autopilot已开启,车辆正在自动行驶...')
#观察30秒
time.sleep(30)
#清理(必须!否则车会留在场景里)
vehicle.destroy()
print('✅车辆已销毁')
代码执行结果:
(carla) lionsking@ai-dev:~/Code/auto_self/carla_ch03$ python 01_spawn_vehicle.py
✅车辆已生成: vehicle.tesla.model3
✅Autopilot已开启,车辆正在自动行驶...
✅车辆已销毁3.2 绑定摄像头 + 数据采集脚本
现在车能自己开了,但我们需要“看到”它看到的世界。下一步是给车辆安装一个前视摄像头,并收集“图像 + 方向盘/油门”的配对数据。
概念解释:模仿学习(Imitation Learning)
模仿学习的思路很简单:找一个“老司机”开给你看,记录他每一刻看到的画面和做的操作,然后训练神经网络学会“看到这个画面就做这个操作”。在 CARLA 中,“老司机”就是 CARLA 内置的 Autopilot(一个基于规则的自动驾驶引擎)。
完整的数据采集脚本:
02_collect_data.py
# 02_collect_data.py
# 采集 CARLA Autopilot 的驾驶数据:图像 + 方向盘 + 油门
import carla, random, time, os, csv
import numpy as np
# ===== 配置 =====
IMG_WIDTH, IMG_HEIGHT = 640, 480
SAVE_DIR = '/data/projects/carla_data'
NUM_FRAMES = 5000 # 采集 5000 帧
# sudo chmod -R 777 /data/projects/carla_data
os.makedirs(f'{SAVE_DIR}/images', exist_ok=True)
# ===== 连接 CARLA =====
client = carla.Client('localhost', 2000)
client.set_timeout(10.0)
world = client.get_world()
# 开启同步模式(确保图像和控制信号帧对齐)
settings = world.get_settings()
settings.synchronous_mode = True
settings.fixed_delta_seconds = 0.05 # 20 FPS
world.apply_settings(settings)
# ===== 生成车辆 =====
bp_lib = world.get_blueprint_library()
vehicle_bp = bp_lib.filter('vehicle.tesla.model3')[0]
spawn_point = random.choice(world.get_map().get_spawn_points())
vehicle = world.spawn_actor(vehicle_bp, spawn_point)
vehicle.set_autopilot(True)
# ===== 安装前视摄像头 =====
camera_bp = bp_lib.find('sensor.camera.rgb')
camera_bp.set_attribute('image_size_x', str(IMG_WIDTH))
camera_bp.set_attribute('image_size_y', str(IMG_HEIGHT))
camera_bp.set_attribute('fov', '110') # 视场角 110°
# 摄像头位置:车前方 1.5米、高度 2.4米
camera_transform = carla.Transform(
carla.Location(x=1.5, z=2.4),
carla.Rotation(pitch=-15) # 微微俯视
)
camera = world.spawn_actor(camera_bp, camera_transform,
attach_to=vehicle)
# ===== 数据采集回调 =====
frame_data = [] # 存储每一帧的数据
current_image = None
def camera_callback(image):
global current_image
# 把 CARLA 图像转为 numpy 数组
array = np.frombuffer(image.raw_data, dtype=np.uint8)
array = array.reshape((IMG_HEIGHT, IMG_WIDTH, 4)) # BGRA
current_image = array[:, :, :3] # 去掉 Alpha 通道
camera.listen(camera_callback)
# ===== 主采集循环 =====
csv_file = open(f'{SAVE_DIR}/labels.csv', 'w', newline='')
writer = csv.writer(csv_file)
writer.writerow(['frame', 'steer', 'throttle', 'brake', 'speed'])
print(f'开始采集 {NUM_FRAMES} 帧数据...')
for frame_id in range(NUM_FRAMES):
world.tick() # 同步模式下手动推进一帧
if current_image is None:
continue
# 获取当前控制信号(Autopilot 的操作)
control = vehicle.get_control()
velocity = vehicle.get_velocity()
speed = (velocity.x**2 + velocity.y**2 + velocity.z**2)**0.5
# 保存图片
import cv2
img_path = f'{SAVE_DIR}/images/frame_{frame_id:06d}.jpg'
cv2.imwrite(img_path, current_image)
# 保存标签
writer.writerow([
frame_id,
round(control.steer, 4), # 方向盘 [-1, 1]
round(control.throttle, 4), # 油门 [0, 1]
round(control.brake, 4), # 刹车 [0, 1]
round(speed, 2) # 速度 m/s
])
if frame_id % 500 == 0:
print(f' 已采集 {frame_id}/{NUM_FRAMES} 帧')
csv_file.close()
camera.stop()
camera.destroy()
vehicle.destroy()
print(f'✅ 采集完成!数据保存在 {SAVE_DIR}')执行结果:
(carla) lionsking@ai-dev:~/Code/auto_self/carla_ch03$ python 02_collect_data.py
开始采集 5000 帧数据...
已采集 500/5000 帧
已采集 1000/5000 帧
已采集 1500/5000 帧
已采集 2000/5000 帧
已采集 2500/5000 帧
已采集 3000/5000 帧
已采集 3500/5000 帧
已采集 4000/5000 帧
已采集 4500/5000 帧
✅ 采集完成!数据保存在 /data/projects/carla_data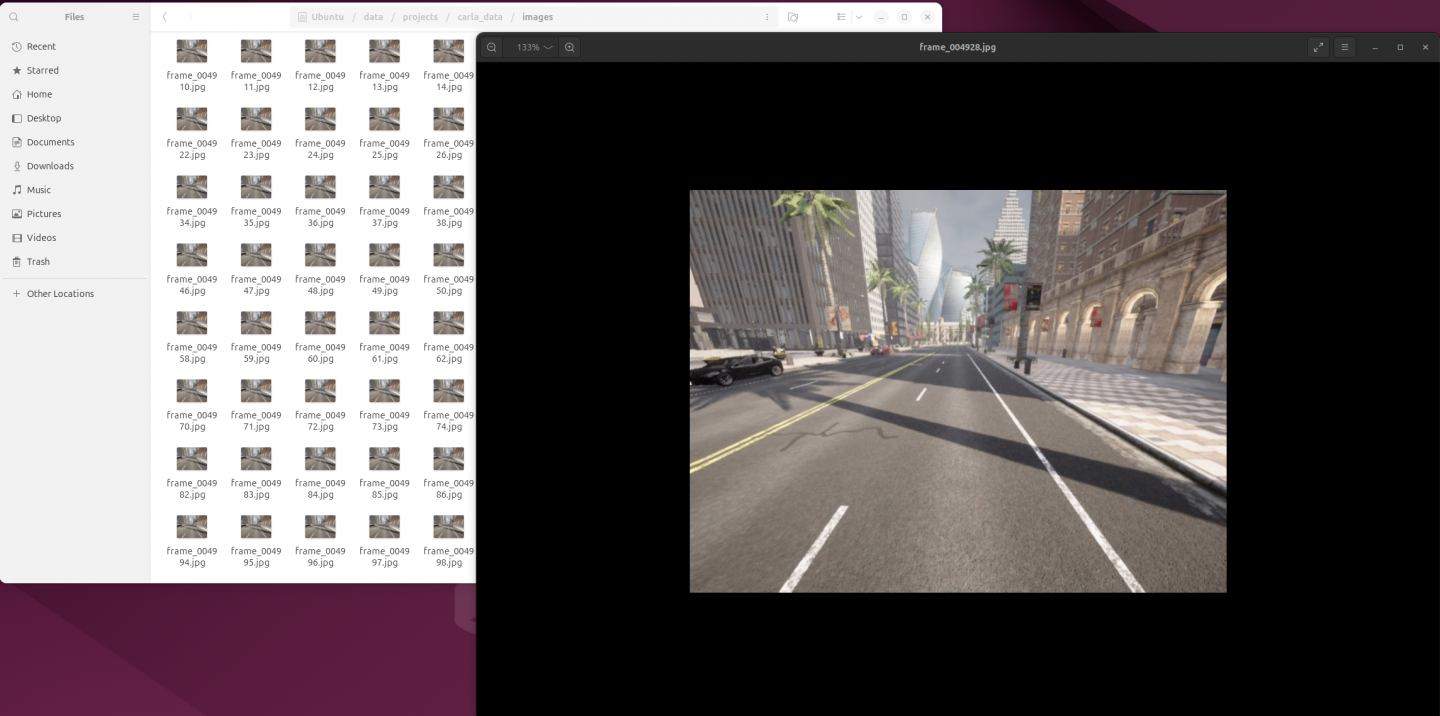
️> 同步模式为什么重要?
异步模式下,CARLA 服务端和 Python 客户端以不同速率运行。你获取的图像和控制信号可能不是同一帧的!同步模式下,服务端会等客户端调用 world.tick() 后才推进一帧,确保数据帧对齐。这对于训练数据的质量至关重要。
3.3 第一个模仿学习模型:ResNet → steer/throttle
3.3.1 模型设计思路
我们的第一个模型非常简单:输入一张摄像头图片,输出方向盘角度和油门深度。用 ResNet-18 作为图像编码器(ImageNet 预训练),后接一个 MLP 头输出控制值。
03_model.py
# 03_model.py
import torch
import torch.nn as nn
import torchvision.models as models
class DrivingModel(nn.Module):
"""
最简单的端到端驾驶模型:
输入:RGB 图像 (3, 224, 224)
输出:steer (-1~1) + throttle (0~1)
"""
def __init__(self):
super().__init__()
# ResNet18:一个超强的图像识别神经网络,18 层。
# 预训练(pretrained=True):它已经在 1400 万张图片上学过边缘、形状、物体、道路、车、人等所有视觉知识。
# 用预训练的 ResNet-18 作为视觉编码器
resnet = models.resnet18(pretrained=True)
# 去掉最后的分类层,只保留特征提取部分
# resnet.children():把 ResNet 所有层拆成一个列表, [:-1]:去掉最后一层(最后一层是 1000 类分类器,对你没用)
# nn.Sequential(...):把剩下的层重新打包
# 命名 backbone = 主干特征提取器
# ✅ 去掉最后一层后,ResNet 变成什么?变成一个纯图像特征提取器,输入图片 → 输出 512 维特征向量
# 把现成 ResNet 的层拆出来再打包
self.backbone = nn.Sequential(*list(resnet.children())[:-1])
# 控制头:512维特征 → 2个输出值
# 自己新建层再打包, 神经网络模块(nn.Module)
# nn.Sequential 是 PyTorch 内置的函数 / 类, 它创建出来的东西,叫 “模块(Module)”
self.control_head = nn.Sequential(
nn.Linear(512, 256), # 第一层:输入512 → 输出256, 作用:把高维特征压缩、提炼关键信息
nn.ReLU(), # 激活函数:增加非线性, 给网络加非线性能力, 没有它,网络再深也只是线性变换,学不会复杂逻辑
nn.Dropout(0.3), ## 随机丢30%神经元,防止过拟合, 防止网络死记硬背训练集(过拟合)
nn.Linear(256, 64), # 第二层:256 → 64, 让网络专注学习 “转向、油门” 相关的特征
nn.ReLU(), # 再激活
nn.Linear(64, 2) # [steer, throttle], # 输出 2 个值:方向盘、油门
)
# 把图像特征 → 变成驾驶动作(输入:512 维特征, 输出:2 个数 → [转向角, 油门])
def forward(self, image):
"""
前向传播 forward(数据怎么流)
这是模型真正运行时的逻辑。
---
3. 去掉之后,后面怎么做?
流程如下:
图片 → 预训练 ResNet(去掉最后一层)→ 512 维特征
512 维特征 → 你的小网络 → 2 个输出值
用 tanh /sigmoid 限制范围 → 得到方向盘、油门
这就叫 迁移学习(Transfer Learning)
---
输入图像 (3×224×224)
↓
预训练 ResNet18(去掉最后一层)→ 提取图像特征
↓
512维特征向量
↓
自定义全连接层(控制头)
↓
输出 2 个值
↓
steer: tanh → [-1, 1]
throttle: sigmoid → [0, 1]
---
六、这个模型的专业名称
端到端自动驾驶模型 + 迁移学习 + ResNet 主干
端到端:图像直接输出控制量
迁移学习:用别人训练好的模型做自己的任务
Backbone:特征提取主干
Head:任务头(输出控制指令)
"""
#(1)图像 → 特征, backbone 就是去掉最后一层的预训练 ResNet
# 输出形状:批量 B × 512 通道 × 1×1(特征图)
# (B, 3, 224, 224)= (批量大小, 通道数, 高度, 宽度)
# 输出: 每张图变成 512 个数字的特征图。
features = self.backbone(image) # (B, 512, 1, 1)
#(2)展平成向量
# 把 512×1×1 展平成 512 维向量
features = features.flatten(1) # (B, 512)
#(3)送入控制头 → 得到 2 个输出
output = self.control_head(features) # (B, 2)
# 输出范围限制(真实驾驶必须)
# steer 用 tanh 限制到 [-1, 1]
# 方向盘 steer:必须在 -1(左)~ 1(右)→ 使用 tanh 自动压缩到 [-1,1]
steer = torch.tanh(output[:, 0])
# 油门 throttle:必须在 0(不踩)~ 1(踩满) → 使用 sigmoid 自动压缩到 [0,1]
# throttle 用 sigmoid 限制到 [0, 1]
throttle = torch.sigmoid(output[:, 1])
return steer, throttle
#-------------------
"""
# 为什么能写成 self.backbone(image)?
# 因为 PyTorch 所有网络层,内部都实现了 __call__
# 只要一个类实现了 __call__,它就能像函数一样使用。这是 Python 规则,不是魔法!
# 举个最简单的例子(你马上懂)
class MyFunction:
def __call__(self, x):
return x * 2
obj = MyFunction()
result = obj(10) # 能调用!像函数一样!
print(result) # 输出 20
# nn.Sequential 内部就像上面的 MyFunction,它实现了 __call__
# self.backbone 是对象, 但能像函数一样调用:self.backbone (参数)
6. 最最最核心总结(你一定能懂)
**self.backbone 是一个 PyTorch 模块
所有 PyTorch 模块都能像函数一样调用:模块 (输入)
调用时必须传输入,因为网络需要输入才能计算
forward 里的 image 就是这个输入 **
7. 用 3 行话彻底终结你的困惑
self.backbone 是神经网络,不是普通变量
神经网络必须接收输入才能运行
所以你写 self.backbone(image),把图片传给它
"""
###04_train.py
# 04_train.py
import torch, os, csv
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
from model_03 import DrivingModel
class DrivingDataset(Dataset):
def __init__(self, data_dir):
self.data_dir = data_dir
# transforms.Compose = 把多个图像处理步骤「打包成一个流水线」
# 把「缩放 → 转张量 → 归一化」这三步,合成一个可调用的函数
# self.transform = transforms.Compose([步骤1, 步骤2, 步骤3])
# 以后使用时,只需要写:img = self.transform(img)
self.transform = transforms.Compose([
transforms.Resize((224, 224)), # Resize(224,224):把图片统一缩成模型能接受的大小
transforms.ToTensor(), # 转成 PyTorch 能用的张量
transforms.Normalize([0.485,0.456,0.406],
[0.229,0.224,0.225]) # 使用 ResNet 预训练必须的标准化值, → 必须和预训练模型匹配,否则效果极差
])
# 读取标签 CSV
self.samples = []
with open(f'{data_dir}/labels.csv') as f:
reader = csv.DictReader(f)
for row in reader:
self.samples.append(row)
def __len__(self): return len(self.samples)
def __getitem__(self, idx):
s = self.samples[idx]
# 1,打开图片
img = Image.open(
f"{self.data_dir}/images/frame_{int(s['frame']):06d}.jpg"
).convert('RGB')
# 2.预处理
# 做预处理(Resize → Tensor → Normalize)
img = self.transform(img)
steer = float(s['steer'])
throttle = float(s['throttle'])
return img, torch.tensor([steer, throttle])
# ===== 训练 =====
dataset = DrivingDataset('/data/projects/carla_data')
loader = DataLoader(dataset, batch_size=32, shuffle=True, num_workers=4)
model = DrivingModel().cuda()
# 优化器 + 损失函数
# optimizer = 大脑, 负责:根据误差,调整模型权重, Adam = 最常用、最稳定的优化器
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
# loss_fn = 评分器, SmoothL1Loss = 回归损失
loss_fn = torch.nn.SmoothL1Loss()
for epoch in range(30):
# 开启训练模式
model.train()
total_loss = 0
# 一批一批读数据
for images, labels in loader:
images, labels = images.cuda(), labels.cuda()
# # 1. 模型前向传播 → 预测
steer_pred, throttle_pred = model(images)
# 2. 拼接预测结果 → [steer, throttle]
pred = torch.stack([steer_pred, throttle_pred], dim=1)
# 3. 计算误差
loss = loss_fn(pred, labels)
# 4. 反向传播 → 改权重
optimizer.zero_grad() ## 清空上一次的梯度
loss.backward() ## 反向传播,计算哪里错了
optimizer.step() # 优化器更新模型,改权重
total_loss += loss.item()
avg_loss = total_loss / len(loader)
print(f'Epoch {epoch+1}/30, Loss: {avg_loss:.4f}')
torch.save(model.state_dict(), 'driving_model.pth')
print('✅ 模型已保存')模型训练结果:
(carla) lionsking@ai-dev:~/Code/auto_self/carla_ch03$ python 04_train.py
/home/lionsking/miniconda3/envs/carla/lib/python3.10/site-packages/torchvision/models/_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
/home/lionsking/miniconda3/envs/carla/lib/python3.10/site-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=ResNet18_Weights.IMAGENET1K_V1`. You can also use `weights=ResNet18_Weights.DEFAULT` to get the most up-to-date weights.
warnings.warn(msg)
Epoch 1/30, Loss: 0.0071
Epoch 2/30, Loss: 0.0005
Epoch 3/30, Loss: 0.0002
Epoch 4/30, Loss: 0.0001
Epoch 5/30, Loss: 0.0001
Epoch 6/30, Loss: 0.0000
...
Epoch 29/30, Loss: 0.0000
Epoch 30/30, Loss: 0.0000
✅ 模型已保存
(carla) lionsking@ai-dev:~/Code/auto_self/carla_ch03$ 05_closed_loop_test.py
import carla, time, torch, cv2
import numpy as np
import random
# torchvision.transforms:PyTorch 官方图像预处理工具
# 用途:把摄像头原始图像 → 变成模型能识别的标准格式
from torchvision import transforms
from model_03 import DrivingModel # 导入自己定义的自动驾驶模型类
# gai模型一般是 CNN/ResNet,输入摄像头画面,输出方向盘转角 + 油门
IMG_WIDTH, IMG_HEIGHT = 640, 480
# 加载训练好的模型
model = DrivingModel().cuda() # .cuda():把模型放到 GPU 上运行,加速推理
# 1,torch.load():加载保存好的模型权重文件
# 2,model.load_state_dict():把权重加载到模型里
model.load_state_dict(torch.load('driving_model.pth'))
# model.eval() 切换到评估模式, 关闭训练时的 Dropout / BatchNorm 等随机化层, 保证推理结果稳定、可复现
model.eval()
# 图像预处理(模型输入标准格式)
# Compose:把多个图像处理步骤打包成一个流水线, 用途:统一摄像头图像 → 模型要求的输入格式
transform = transforms.Compose([
transforms.ToPILImage(), # 把 numpy 格式的图像 → 转成 PIL 图像, 因为 PyTorch 预处理工具优先支持 PIL
transforms.Resize((224, 224)),# 把图像缩放到 224x224,这是绝大多数图像模型(ResNet/MobileNet)的标准输入尺寸
transforms.ToTensor(), # 把图像 → 转为 PyTorch 张量(Tensor)
transforms.Normalize([0.485,0.456,0.406], [0.229,0.224,0.225]) # 形状从 (H, W, 3) → (3, H, W),数值归一化到 0~1, 用途:让你的图像和训练时的数据分布一致,模型预测才准
# ImageNet 标准归一化, 两个数组分别是:RGB 三通道均值、标准差
])
# ====================== 连接 CARLA 并开启同步模式 ======================
# 连接 CARLA,生成车辆和摄像头(同 02 脚本)
client = carla.Client('localhost', 2000)
client.set_timeout(10.0)
world = client.get_world()
# 【修复 1】强制开启同步模式,保证车辆不消失、不卡顿
settings = world.get_settings()
settings.synchronous_mode = True
settings.fixed_delta_seconds = 0.05 # 20 FPS 稳定仿真
world.apply_settings(settings)
world.tick() # 必须先 tick 一次让设置生效
time.sleep(0.5)
# ====================== 生成车辆(固定在地图起点,你能直接看到) =====================
bp_lib = world.get_blueprint_library()
vehicle_bp = bp_lib.filter('vehicle.tesla.model3')[0]
# 【修复 2】不随机!固定在第一个出生点,保证你能看到车
spawn_points = world.get_map().get_spawn_points()
spawn_point = spawn_points[0] # 固定位置,不再随机
# spawn_point = random.choice(world.get_map().get_spawn_points())
# vehicle = world.spawn_actor(vehicle_bp, spawn_point)
# vehicle.set_autopilot(True)
# 【修复 3】安全生成车辆,失败会提示,不会崩溃
vehicle = None
for i in range(10):
try:
vehicle = world.spawn_actor(vehicle_bp, spawn_point)
print("✅ 车辆生成成功!")
break
except:
spawn_point = spawn_points[i]
time.sleep(0.3)
if vehicle is None:
raise Exception("❌ 车辆生成失败,退出程序")
# ====================== 安装摄像头 + 【修复 4:添加回调函数】 ======================
camera_bp = bp_lib.find('sensor.camera.rgb')
camera_bp.set_attribute('image_size_x', str(IMG_WIDTH))
camera_bp.set_attribute('image_size_y', str(IMG_HEIGHT))
camera_bp.set_attribute('fov', '110') # 视场角 110°
# 摄像头位置:车前方 1.5米、高度 2.4米
camera_transform = carla.Transform(
carla.Location(x=1.5, z=2.4),
carla.Rotation(pitch=-15) # 微微俯视
)
camera = world.spawn_actor(camera_bp, camera_transform,
attach_to=vehicle)
# fix bug:
# 摄像头没有设置回调函数 → current_image 永远是 None → 车辆永远不执行控制
# 你创建了摄像头,但没有写回调接收图像,所以 current_image 永远是 None,车辆永远不动,你也看不到控制效果。
# ===== 闭环控制循环 =====
current_image = None # 回调更新, 存储最新一帧摄像头图像, 由摄像头回调函数实时更新
# 【关键修复】摄像头回调函数 → 接收图像并赋值给 current_image
def image_callback(image):
global current_image
array = np.frombuffer(image.raw_data, dtype=np.uint8)
array = array.reshape((IMG_HEIGHT, IMG_WIDTH, 4))
array = array[:, :, :3] # 去掉 Alpha 通道
current_image = array
camera.listen(image_callback) # 启动监听
# ====================== 闭环控制 ======================
collision_count = 0 # 碰撞计数器:记录车辆撞墙 / 撞车次数(代码里没写检测逻辑,只是占位)
total_distance = 0.0 # 总行驶距离
print("开始自动驾驶...")
for step in range(2000): # 跑 2000 步
# 让世界往前走一帧,更新所有物体位置、传感器数据
world.tick() # # 推动仿真
# 如果还没收到摄像头图像,跳过这一步, 防止程序崩溃
if current_image is None:
continue
# 模型推理
# transform(current_image):用流水线预处理图像, .unsqueeze(0):增加 batch 维度
# 模型输入要求:(batch, 3, 224, 224)
# .cuda():把图像数据放到 GPU,和模型在一起
img_tensor = transform(current_image).unsqueeze(0).cuda()
# 关闭梯度计算, 推理时不需要反向传播,能省显存、提速
with torch.no_grad():
steer, throttle = model(img_tensor)
# ==============================================
# 【终极修复 1】强制油门 = 0.5 (直接让车跑起来)
# ==============================================
# min(float(throttle.item()) * 2000, 1.0)
actual_throttle = 0.5
# 用模型输出控制车辆(而不是 Autopilot!)
vehicle.apply_control(carla.VehicleControl(
steer=float(steer.item()), # 把模型输出的张量 → 转成 Python 浮点数
throttle=actual_throttle, # 强制放大油门
brake=0.0, # 不刹车(你可以扩展:根据速度 / 距离自动刹车)
hand_brake=False, # 必须加!松开手刹
manual_gear_shift=True, # 手动挡
gear=1 # 1挡前进
))
if step % 100 == 0:
v = vehicle.get_velocity() # 获取车辆 3D 速度向量(x/y/z)
speed = (v.x**2 + v.y**2 + v.z**2)**0.5 # 计算合速度(m/s), 欧几里得距离公式
print(f'Step {step}: steer={steer.item():.3f}, '
f'throttle={throttle.item():.3f}, speed={speed:.1f}m/s')
# ====================== 清理资源 ======================
camera.stop()
camera.destroy()
vehicle.destroy()
# 恢复CARLA设置
settings = world.get_settings()
settings.synchronous_mode = False
world.apply_settings(settings)
print("\n✅ 闭环测试完成!")
print(f'✅ 闭环测试完成!碰撞次数: {collision_count}')
执行记录:
(carla) lionsking@ai-dev:~/Code/auto_self/carla_ch03$ python 05_closed_loop_test.py
/home/lionsking/miniconda3/envs/carla/lib/python3.10/site-packages/torchvision/models/_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
/home/lionsking/miniconda3/envs/carla/lib/python3.10/site-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=ResNet18_Weights.IMAGENET1K_V1`. You can also use `weights=ResNet18_Weights.DEFAULT` to get the most up-to-date weights.
warnings.warn(msg)
✅ 车辆生成成功!
开始自动驾驶...
Step 100: steer=-0.020, throttle=0.010, speed=8.5m/s
Step 200: steer=0.022, throttle=0.005, speed=0.0m/s
Step 300: steer=0.035, throttle=0.004, speed=0.0m/s
Step 400: steer=0.029, throttle=0.004, speed=0.0m/s
Step 500: steer=0.042, throttle=0.003, speed=0.0m/s
Step 600: steer=0.023, throttle=0.002, speed=0.0m/s
Step 700: steer=0.061, throttle=0.002, speed=0.0m/s
Step 800: steer=0.064, throttle=0.003, speed=0.0m/s
Step 900: steer=0.053, throttle=0.003, speed=0.0m/s
Step 1000: steer=0.049, throttle=0.003, speed=0.0m/s
Step 1100: steer=0.028, throttle=0.005, speed=0.0m/s
Step 1200: steer=0.031, throttle=0.005, speed=0.0m/s
Step 1300: steer=0.005, throttle=0.006, speed=0.0m/s
Step 1400: steer=0.004, throttle=0.006, speed=0.0m/s
Step 1500: steer=-0.005, throttle=0.006, speed=0.0m/s
Step 1600: steer=0.021, throttle=0.006, speed=0.0m/s
Step 1700: steer=0.027, throttle=0.004, speed=0.0m/s
Step 1800: steer=0.015, throttle=0.003, speed=0.0m/s
Step 1900: steer=0.034, throttle=0.004, speed=0.0m/s
✅ 闭环测试完成!
✅ 闭环测试完成!碰撞次数: 0
(carla) lionsking@ai-dev:~/Code/auto_self/carla_ch03$ 新的模拟闭环
import carla
import torch
import cv2
import numpy as np
import time
import random
from torchvision import transforms
from model_03 import DrivingModel
# ===================== 固定尺寸 =====================
IMG_WIDTH, IMG_HEIGHT = 400, 200
# ===================== 视频录制 =====================
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
video = cv2.VideoWriter('test_run.mp4', fourcc, 20, (IMG_WIDTH, IMG_HEIGHT))
# ===================== 加载模型 =====================
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
model = DrivingModel().to(DEVICE)
# 直接加载权重,忽略层名不匹配
state_dict = torch.load('driving_model.pth', map_location=DEVICE)
#model.load_state_dict(torch.load('driving_model.pth', map_location=DEVICE))
model.load_state_dict(state_dict, strict=False) # strict=False 跳过名字不匹配
model.eval()
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) #
])
# ===================== 连接 CARLA =====================
client = carla.Client('localhost', 2000)
client.set_timeout(10.0)
world = client.get_world()
# 同步模式(必须开)
settings = world.get_settings()
settings.synchronous_mode = True
settings.fixed_delta_seconds = 0.05
world.apply_settings(settings)
# 清理旧物体
for actor in world.get_actors().filter('*vehicle*'):
actor.destroy()
for sensor in world.get_actors().filter('*sensor*'):
sensor.destroy()
# ===================== 生成车辆 =====================
bp_lib = world.get_blueprint_library()
vehicle_bp = bp_lib.filter('vehicle.tesla.model3')[0]
spawn_point = random.choice(world.get_map().get_spawn_points())
vehicle = world.spawn_actor(vehicle_bp, spawn_point)
# 视角跟随车辆
spectator = world.get_spectator()
# ===================== 摄像头 =====================
camera_bp = bp_lib.find('sensor.camera.rgb')
camera_bp.set_attribute('image_size_x', str(IMG_WIDTH))
camera_bp.set_attribute('image_size_y', str(IMG_HEIGHT))
camera_bp.set_attribute('fov', '110')
camera_transform = carla.Transform(
carla.Location(x=2.5, z=0.7),
carla.Rotation(pitch=-15)
)
camera = world.spawn_actor(camera_bp, camera_transform, attach_to=vehicle)
latest_image = None
def camera_callback(image):
global latest_image
array = np.frombuffer(image.raw_data, dtype=np.uint8)
array = array.reshape((IMG_HEIGHT, IMG_WIDTH, 4))[:, :, :3]
latest_image = array
camera.listen(camera_callback)
# ===================== 主驾驶循环 =====================
total_distance = 0
prev_location = vehicle.get_transform().location
print("开始 AI 驾驶...")
for step in range(1500):
world.tick()
if latest_image is None:
continue
# 视角跟随
try:
v_trans = vehicle.get_transform()
spectator.set_transform(carla.Transform(
carla.Location(
x=v_trans.location.x - 8,
y=v_trans.location.y,
z=v_trans.location.z + 4
),
carla.Rotation(pitch=-30)
))
except:
pass
# 图像预处理
img_rgb = cv2.cvtColor(latest_image, cv2.COLOR_BGR2RGB)
img_tensor = transform(img_rgb).unsqueeze(0).to(DEVICE)
# 推理
with torch.no_grad():
pred = model(img_tensor)[0].cpu().numpy()
# ===================== 修复:转成原生 float =====================
steer = float(np.clip(pred[0], -1.0, 1.0))
#throttle = float(np.clip(pred[1], 0.2, 0.5))
throttle = 0.4 # 固定油门,车一定动
# 车辆控制(绝对不报错)
control = carla.VehicleControl()
control.steer = steer
control.throttle = throttle
control.brake = 0.0
vehicle.apply_control(control)
# 计算距离
now_loc = vehicle.get_transform().location
total_distance += now_loc.distance(prev_location)
prev_location = now_loc
# 显示 + 写视频
display = latest_image.copy()
cv2.putText(display, f'Steer: {steer:.2f}', (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2)
cv2.putText(display, f'Throttle: {throttle:.1f}', (10, 60),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2)
video.write(display)
#cv2.imshow("AI Driving", display)
#if cv2.waitKey(1) & 0xFF == ord('q'):
# break
# ===================== 释放资源 =====================
video.release()
#cv2.destroyAllWindows()
vehicle.destroy()
camera.destroy()
print(f'行驶距离: {total_distance:.1f} 米')
print("视频已保存:test_run.mp4")
打印日志:
(carla) lionsking@ai-dev:~/Code/auto_self/carla_ch03$ python 06_closed_loop_test.py
/home/lionsking/miniconda3/envs/carla/lib/python3.10/site-packages/torchvision/models/_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
/home/lionsking/miniconda3/envs/carla/lib/python3.10/site-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=ResNet18_Weights.IMAGENET1K_V1`. You can also use `weights=ResNet18_Weights.DEFAULT` to get the most up-to-date weights.
warnings.warn(msg)
开始 AI 驾驶...

为者常成,行者常至
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)



